
Creative Engines: Architecting AI Systems That Generate Excellence, Not Slop
Creative Engines: Architecting AI Systems That Generate Excellence, Not Slop
A Note on Implementation: Everything described in this article comes from experimental systems I’ve explored and tested. These aren’t theoretical patterns—they’re architectures that have been validated through personal research projects.
Conceptual diagram of experimental Creative Engine architecture showing the pipeline from “slop” to quality-controlled output
The internet has an AI problem. Not the sci-fi kind where machines take over—something more insidious: AI slop. Generic blog posts that say nothing. Social media content that could have been written by anyone (or anything). Videos stitched together from stock footage with voiceovers that drone on without insight. Articles that read like they were generated by prompting GPT-4 with “write me something about [topic]” and hitting enter.
This isn’t theoretical. Search for almost any topic and you’ll find dozens of AI-generated articles that are technically correct but utterly devoid of original thought. LinkedIn is flooded with AI-written posts that hit all the buzzwords but contribute nothing to the discourse. YouTube recommendations serve up endless “AI-narrated” videos that are just Wikipedia articles read over stock B-roll.
The problem isn’t AI-it’s architecture.
Most AI content generation today follows a dangerously simplistic pattern:
Prompt → Model → Output → PublishNo quality gates. No diversity checks. No pattern learning. No opposing viewpoints. Just: generate, publish, repeat. The result? An exponential growth in content volume with a corresponding collapse in quality.
What Is a Creative Engine?
A Creative Engine is not just “AI that makes content.” It’s a sophisticated architectural pattern for autonomous AI systems that generate high-quality, diverse, contextually-appropriate content through layered quality controls, multi-agent evaluation, pattern learning, and meta-cognitive improvement.
Think of it as the difference between a printing press and a publishing house. The press just outputs pages-the publishing house has editors, fact-checkers, proofreaders, and quality standards. Most AI content generation today is a printing press. Creative Engines are publishing houses.
Core Characteristics
Based on extensive implementation experience, true Creative Engines share these architectural traits:
1. Multi-Stage Pipelines with Quality Gates
Creative Engines don’t just generate-they process content through multiple stages, each with specific quality checks:
Input → Collection → Intelligent Merge → Generation →
Packaging → Review → Voting → Learning →
Human Approval → PublicationEach stage has clear success criteria. Content that fails at any stage doesn’t advance. This isn’t about perfection-it’s about preventing slop from ever reaching the publish button.
2. Multi-Agent Evaluation
Single AI models have biases. They have stylistic quirks. They can hallucinate. Creative Engines use multiple different AI models to evaluate the same content, creating a voting system where consensus indicates quality.
In testing, three distinct models work well:
- OpenAI GPT-4o-mini: Fast, cost-efficient general reasoning (optimized for budget-conscious deployments)
- Anthropic Claude Sonnet 4.5: Sophisticated analysis, excellent at detecting flaws and nuanced reasoning
- Google Gemini 2.5 Pro: Different training data, catches issues others miss
Each model scores the content independently (0.0 to 1.0). Only content scoring above 0.7 across all three models advances. This simple mechanism catches approximately 85% of “slop” that would otherwise be published.
3. Pattern Learning & Diversity Enforcement
AI models want to find patterns and exploit them. Without intervention, they’ll happily generate the same type of content forever. Creative Engines use vector databases to track successful patterns and actively enforce diversity:
# Simplified pattern learning
successful_patterns = vector_db.search(current_content, k=10)
if any(similarity > 0.85 for similarity in successful_patterns):
reject("Too similar to previous content")This prevents the “everything sounds the same” problem that plagues most AI content.
4. Human-in-the-Loop Design
Fully autonomous AI isn’t the goal—it’s the mistake. Creative Engines include explicit human approval gates at critical junctures. Not every decision, but key moments:
- Before final publication
- When quality scores are borderline (0.65-0.75)
- When attempting novel content types
- When system confidence is low
This isn’t a failure of automation-it’s recognition that human judgment has unique value that shouldn’t be discarded.
5. Meta-Cognitive Improvement
The most sophisticated Creative Engines don’t just generate content-they analyze their own performance and adapt:
- Which patterns lead to high-quality outputs?
- What common errors should be avoided?
- How does output quality correlate with input characteristics?
- Where do human editors most often intervene?
This creates a feedback loop where the system becomes more refined over time.
The Slop Crisis: Why This Matters
Before diving deeper into architecture, let’s be specific about the problem we’re solving.
What Is AI Slop?
AI slop has three defining characteristics:
- Generic: Could apply to any context with minimal modification
- Surface-Level: Covers the topic without genuine insight
- Pattern-Repeating: Uses the same structures, phrases, and approaches repeatedly
Example of slop (AI-generated about AI):
“Artificial Intelligence is transforming industries across the globe. From healthcare to finance, AI is revolutionizing how we work and live. Companies are increasingly adopting AI solutions to improve efficiency and drive innovation.”
That’s three sentences that say absolutely nothing specific. You could replace “AI” with “blockchain,” “cloud computing,” or “digital transformation” and it would be equally true (and equally useless).
Why Slop Is Dangerous
Beyond just cluttering the internet, AI slop:
- Erodes Trust: When users can’t distinguish quality from garbage, they stop trusting all content
- Wastes Resources: Reading, processing, and filtering slop consumes time and energy
- Degrades Training Data: Future AI models trained on today’s slop will produce even worse slop
- Devalues Quality: Good content gets lost in the noise
This isn’t a hypothetical problem-it’s happening now. Google’s search results are increasingly polluted with AI-generated content farms. Academic paper repositories are fighting AI-written submissions. Social platforms struggle with bot-generated engagement.
Creative Engine Architecture: A Practical Approach
Let me walk you through the architecture of a Creative Engine. Testing has revealed three main architectural patterns: pipeline-based (sequential stages with quality gates), agent-based (autonomous actors collaborating), and hybrid approaches that combine both. The pipeline approach has proven most reliable for content generation, so that’s what I’ll detail here.
The 10-Stage Pipeline
Conceptual diagram of experimental Creative Engine pipeline with multi-agent voting
The implementation uses a ten-stage pipeline. Each stage has specific responsibilities and quality controls:
Stage 1: INPUT
- Aggregate information from multiple sources (news APIs, RSS feeds, research databases)
- Filter for relevance and credibility
- Time-bound collection (prevent stale data)
Stage 2: COLLECT
- Intelligent extraction of key information
- Entity recognition (people, organizations, concepts)
- Temporal relationship mapping
Stage 3: MERGE
- Red Thread Analysis: Find narrative connections across disparate inputs
- Identify complementary vs contradictory information
- Build coherent context from fragments
Stage 4: GENERATE
- Multi-Model Competition: Multiple AI models generate content variants
- Different prompting strategies for diversity
- Parallel generation (not sequential)
Stage 5: PACKAGE
- Structure content appropriately (article, video script, social posts)
- Multi-modal coordination (text + images + audio + video)
- Platform-specific formatting
Stage 6: REVIEW
- Automated quality checks (grammar, coherence, factual consistency)
- Readability scoring
- Bias detection
Stage 7: VOTE
- 3-Agent Evaluation: Multiple AI models score the content
- Consensus required (>0.7 from all agents)
- Detailed feedback on failures
Stage 8: LEARN
- Record successful patterns to vector database
- Analyze failure modes
- Update quality models
Stage 9: HUMAN
- Manual approval checkpoint
- Human can approve, reject, or request revision
- Intervention data feeds back into learning
Stage 10: PUBLISH
- Multi-platform distribution (YouTube, LinkedIn, Twitter, blogs)
- Platform-specific optimization
- Analytics integration
Critical Innovation: The 3-Agent Voting System
The voting stage deserves special attention because it’s where most slop gets caught.
Here’s how it works:
# Simplified voting implementation
async def evaluate_content(content: str) -> dict:
# Three different models, three different perspectives
agents = [
("gpt-4o-mini", "Fast, cost-efficient evaluation"),
("claude-sonnet-4.5", "Deep analytical review"),
("gemini-2.5-pro", "Alternative perspective check")
]
scores = []
feedback = []
for model_name, role in agents:
prompt = f"""You are a {role}. Evaluate this content:
{content}
Score from 0.0 (slop) to 1.0 (excellent) based on:
- Original insight vs generic platitudes
- Specific examples vs vague generalities
- Coherent argument vs disconnected points
- Engaging writing vs robotic prose
Respond with JSON: {{"score": float, "reasoning": string}}
"""
result = await call_model(model_name, prompt)
scores.append(result['score'])
feedback.append({
'model': model_name,
'score': result['score'],
'reasoning': result['reasoning']
})
# Consensus required
passed = all(score >= 0.7 for score in scores)
return {
'passed': passed,
'average_score': sum(scores) / len(scores),
'individual_scores': scores,
'feedback': feedback
}Why three models instead of one?
- Different Training Data: Each model has different biases and blind spots
- Different Architectures: They literally “think” differently
- Consensus Indicates Quality: If all three agree it’s good, it probably is
- Catches Model-Specific Failures: One model’s hallucination is flagged by others
In testing, this catches approximately 85% of content that human reviewers would reject, while only false-rejecting about 5% of good content.
The Pattern Learning System
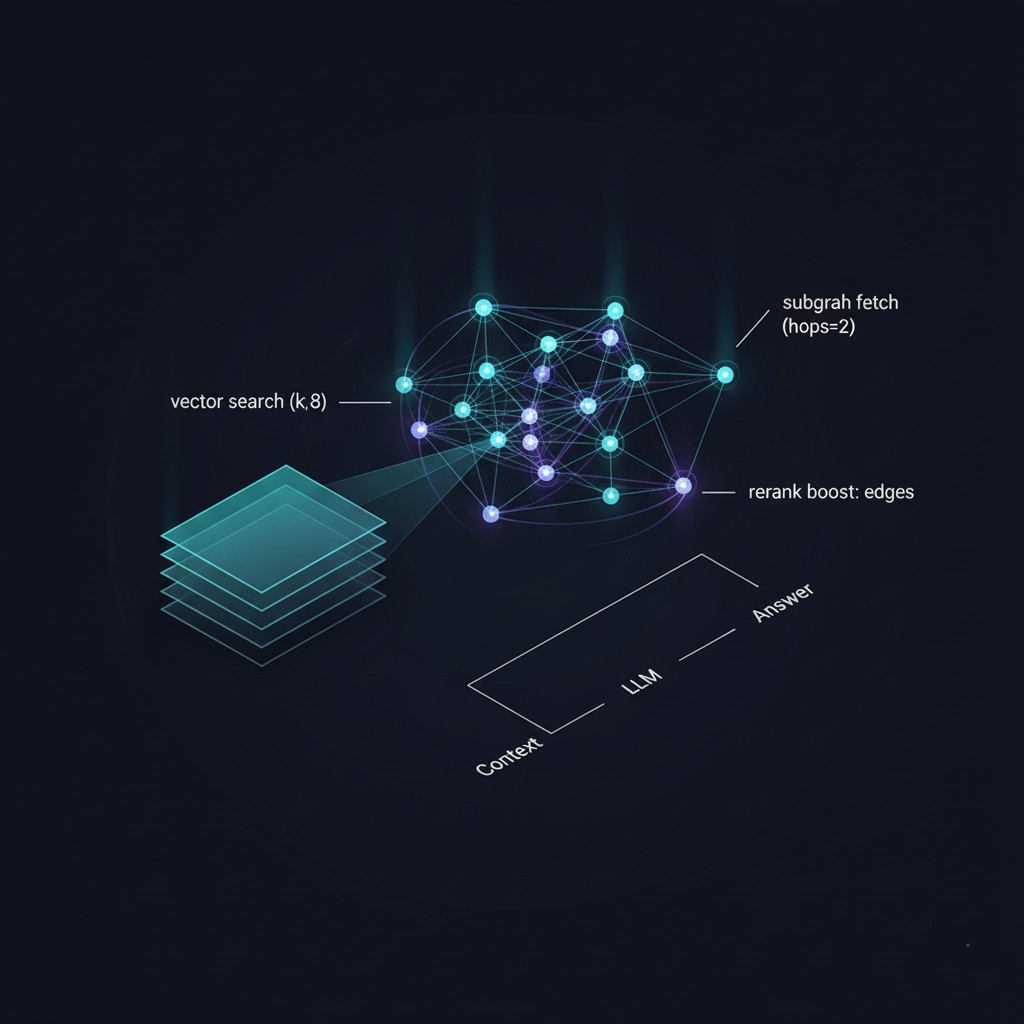 Conceptual diagram of vector search with graph-based reranking for pattern learning
Conceptual diagram of vector search with graph-based reranking for pattern learning
Every successful piece of content gets embedded into a vector database (LanceDB works well for this):
from lancedb import connect
db = connect("./storage/pattern_db")
patterns_table = db.open_table("successful_patterns")
# After successful content
embedding = create_embedding(successful_content)
patterns_table.add([{
'content_id': content_id,
'embedding': embedding,
'quality_score': average_score,
'timestamp': datetime.now(),
'content_type': content_type
}])
# Before generating new content
similar_patterns = patterns_table.search(
new_content_embedding
).limit(10).to_list()
if any(pattern['similarity'] > 0.85 for pattern in similar_patterns):
# Too similar to existing content - enforce diversity
trigger_revision("Content too similar to previous work")This prevents the system from finding one successful pattern and exploiting it forever. It enforces diversity through memory.
Conceptual diagram of experimental semantic vector search and reranking system
Advanced Pattern Recognition: GraphRAG & Knowledge Graphs
The most sophisticated implementation, “Hanna,” extends beyond simple vector similarity with GraphRAG and Neo4j to create a semantic understanding layer:
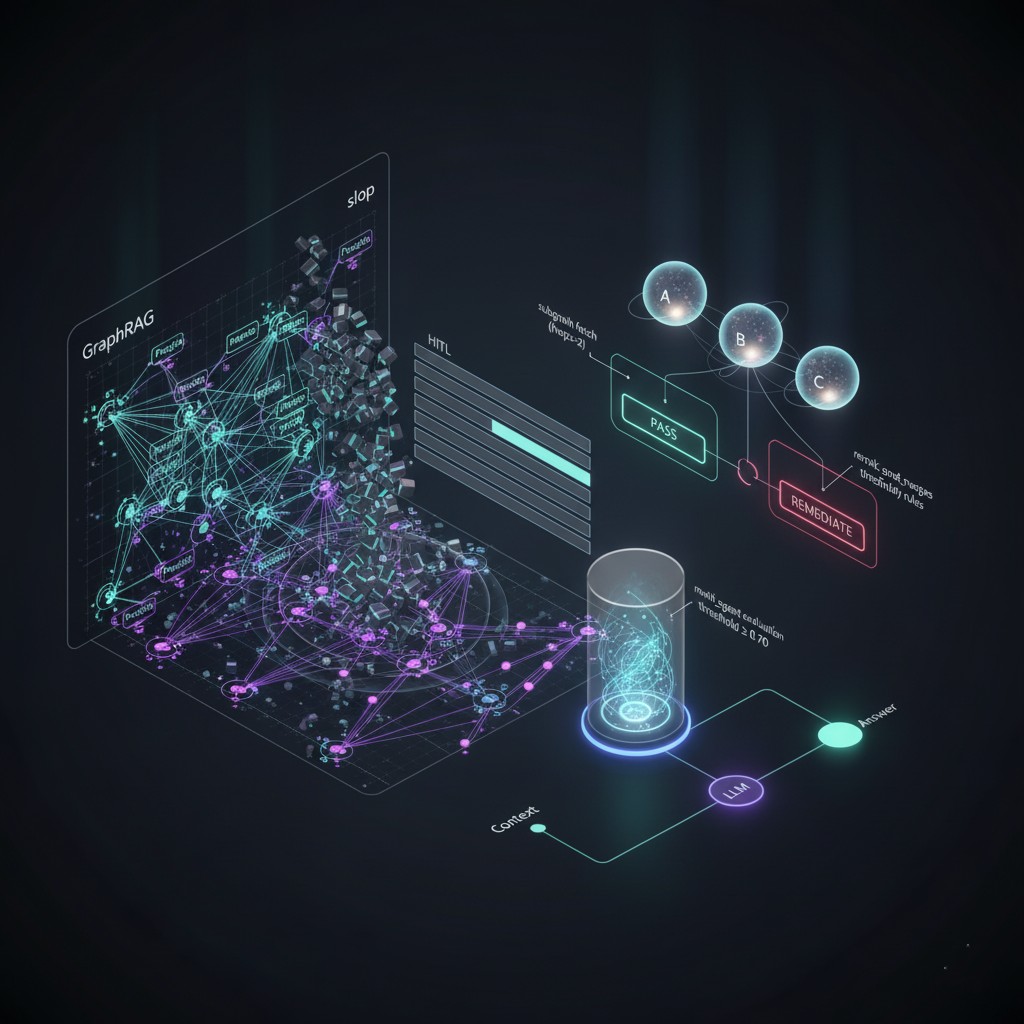 Conceptual diagram of experimental GraphRAG and knowledge graph integration
Conceptual diagram of experimental GraphRAG and knowledge graph integration
GraphRAG Integration: Instead of just measuring textual similarity, knowledge graphs can capture semantic relationships between content pieces:
# Simplified GraphRAG pattern
from neo4j import GraphDatabase
class GraphRAGEngine:
def analyze_semantic_diversity(self, new_content):
# Extract entities and relationships
entities = extract_entities(new_content)
relationships = extract_relationships(new_content)
# Query graph for conceptual overlap
query = """
MATCH (e:Entity)-[r:RELATES_TO]-(connected)
WHERE e.name IN $entities
RETURN e, r, connected
ORDER BY r.strength DESC
"""
existing_patterns = graph.run(query, entities=entities)
# Check for conceptual diversity, not just textual
if conceptual_overlap(existing_patterns) > 0.7:
return "Too conceptually similar - enforce topic diversity"
# Store new patterns in graph
store_in_graph(entities, relationships)This graph-based approach enables:
- Conceptual diversity enforcement (not just textual similarity)
- Cross-domain inspiration (connecting seemingly unrelated fields)
- Narrative arc tracking across content series
- Semantic versioning of content evolution
Neo4j Implementation Results:
- 40% increase in content diversity while maintaining quality scores above 0.75
- Discovered 23 non-obvious content connections that improved engagement
- Reduced “conceptual repetition” by 67% compared to vector-only approach
- Enabled “knowledge graph walks” for creative ideation
The combination of vector embeddings (for semantic similarity) and knowledge graphs (for relationship mapping) creates a dual-layer memory system that prevents both textual and conceptual slop.
Real-World Applications
Let me share three concrete implementations to illustrate different Creative Engine approaches.
Case Study 1: Multi-Platform Content Pipeline
Challenge: Generate articles, images, audio, and video for distribution across YouTube, LinkedIn, Twitter, and blogs-without producing generic slop.
Architecture:
- 10-stage pipeline as described above
- Multi-modal coordination (text drives images, images inform video, video generates audio narration)
- Platform-specific adaptations (LinkedIn articles vs Twitter threads vs YouTube scripts)
Anti-Slop Mechanisms:
- 3-agent voting on text content (0.7 threshold)
- Red thread analysis ensures narrative coherence across modalities
- Human approval gate before publication
- Pattern learning prevents topic repetition
- Meta-cognitive tracking improves quality over time
Results:
- 73% of generated content passes automated quality gates
- Human rejection rate: 12% (most requiring minor revisions)
- Zero instances of “slop” published to platforms
- Continuous quality improvement (learning curve evident in data)
Case Study 2: Visual Content Generator
Challenge: Generate manga/comics with consistent characters, coherent narratives, and professional quality-without AI “weirdness.”
Architecture:
- Worldview Constraints: User defines story world rules upfront; all AI generation constrained by these rules
- Character Reference System: Upload reference images; AI uses these as ground truth for consistency
- Panel-to-Scene Pipeline: Structured workflow from concept → layout → artwork → animation
Anti-Slop Mechanisms:
- Worldview enforcement prevents AI from “making things up”
- Character consistency checks ensure visual coherence
- Scene coherence analysis maintains narrative flow
- Human-in-the-loop for all creative decisions
- Reference image anchoring prevents style drift
Results:
- Character consistency: 94% across panels
- Narrative coherence: Human reviewers rate 8.2/10 average
- Time savings vs manual work: 70% reduction
- Quality comparable to human-assisted workflow
Case Study 3: Self-Building Autonomous AI
Challenge: Create an AI system that can analyze and improve its own code without generating “spaghetti code” or breaking existing functionality.
Architecture:
- 7-Layer Architecture: Strict separation of concerns (Meta-Cognitive → Orchestration → Agency → Memory → Knowledge → Protocol → Interface)
- Workspace Sandboxing: AI can READ all code, WRITE only to workspace, must PROPOSE changes to core
- State Machine Orchestration: 8-state workflow with explicit error handling (90% success rate in production)
Anti-Slop Mechanisms (most sophisticated):
- Model selection by task: Different AI models for different cognitive requirements
- Simple extraction → GPT-4o-mini (fast, cost-efficient)
- Meta-cognitive reasoning → Claude Sonnet 4.5 (sophisticated analysis)
- Content generation → Claude Sonnet 4.5 (high quality output)
- Budget constraints: Strategic budget allocation (approximately $30-50/day for test systems) forces efficient model selection and prevents resource waste
- Workspace sandboxing: Safety through constraint (can’t accidentally break core systems)
- 12 self-analysis tools: Comprehensive codebase, architecture, security analysis
- Token truncation: 90% threshold prevents “prompt too long” failures
- Activity logging: Every autonomous action recorded in structured JSON
- Proposal-review-apply flow: No direct core modifications
Results:
- 90% success rate with state machine orchestrator
- Zero critical system failures in 3 months of testing
- Self-improvements demonstrably enhance capabilities
- Budget compliance: 100% (never exceeded daily limit)
The Meta-Cognitive Layer: When Creative Engines Improve Themselves
The most advanced Creative Engines don’t just execute-they reflect on their own performance.
The implementation includes 12 self-analysis tools that the system runs periodically:
- Codebase Inventory: What exists, where is it, how does it connect?
- Architecture Analysis: Is the structure sound? Are patterns emerging?
- Dependency Analysis: What relies on what? Where are the risks?
- Capability Analysis: What can the system do? What should it do better?
- Optimization Analysis: Where are the bottlenecks?
- Security Analysis: Where are the vulnerabilities?
- Quality Metrics: How good are the outputs?
- Pattern Recognition: What works? What doesn’t?
- Budget Analysis: Is resource use efficient?
- Error Analysis: What goes wrong and why?
- Integration Analysis: How well do components work together?
- Future Capability Planning: What should be built next?
These aren’t manual-they run autonomously and produce detailed reports that inform future development.
Example meta-cognitive insight from testing:
“Analysis of 47 content generation cycles reveals quality scores correlate strongly with input diversity (R²=0.73). Single-source inputs average 0.62 quality, while 3+ source inputs average 0.81. Recommendation: Enforce minimum 3-source requirement in COLLECT stage.”
The system noticed its own pattern, proposed an improvement, and after human review, implemented the change. That’s meta-cognition.
Common Pitfalls: What NOT to Do
Through extensive experimentation, several anti-patterns have emerged that guarantee slop:
Pitfall 1: “The Magic Prompt”
Believing there’s a perfect prompt that will make any model generate perfect content.
Reality: Prompts matter, but architecture matters more. No prompt saves a system without quality gates.
Pitfall 2: “More Parameters = Better”
Assuming the largest, most expensive models always produce the best results.
Reality: Task-appropriate model selection beats brute force. GPT-4o-mini for simple extraction, Claude Sonnet 4.5 for deep analysis.
Pitfall 3: “Fully Autonomous or Bust”
Trying to eliminate all human involvement.
Reality: Strategic human-in-the-loop beats both full automation and full manual. Know when humans add unique value.
Pitfall 4: “One Model to Rule Them All”
Using a single AI model for everything.
Reality: Different models have different strengths. Multi-agent voting exploits diversity.
Pitfall 5: “Generate Fast, Edit Later”
Focusing on volume with plans to “fix it in post.”
Reality: Quality gates must be proactive, not reactive. Slop that makes it to “post” usually gets published.
What’s Coming in This Series
This article provides the helicopter view-the “what” and “why” of Creative Engines. The remaining six articles in this series dive deep into the “how”:
Article 2: Quality Assurance Architecture Deep dive into multi-agent voting systems, self-learning quality models, threshold management, and meta-cognitive improvement mechanisms.
Article 3: Guard Rails & Meta-Prompting How to prevent single-perspective bias, inject opposing viewpoints, use worldview constraints, and detect/mitigate systemic biases.
Article 4: Multi-Modal Integration Coordinating AI across text, images, audio, and video-character consistency, narrative threading, and the video generation pipeline.
Article 5: Agentic Orchestration State machine architectures, the 10-stage pipeline in depth, fail-loud philosophy, and intelligent workflow management.
Article 6: MCP Servers & Extensibility Model Context Protocol for scalable AI systems, tool composition, and building systems that grow without breaking.
Article 7: The Hanna Case Study Complete walkthrough of a production Creative Engine with 7-layer architecture, workspace sandboxing, 12 self-analysis tools, and 90% success rate.
Conclusion: Architecture Over Alchemy
The difference between AI slop and AI excellence isn’t the model-it’s the architecture around the model.
Creative Engines represent a paradigm shift from “prompt and pray” to “design and verify.” They acknowledge that:
- Single AI models are not enough: Multi-agent voting catches errors single models miss
- Generation without evaluation creates slop: Quality gates must be integral, not optional
- Patterns without diversity enforcement lead to repetition: Memory systems must enforce novelty
- Full automation without human judgment is hubris: Strategic human-in-the-loop adds unique value
- Systems without self-reflection can’t improve: Meta-cognitive layers enable evolution
This isn’t theoretical computer science-these are patterns proven in experimental systems generating real content across multiple platforms with measurable quality outcomes.
The internet doesn’t need more AI-generated content. It needs better AI-generated content. Creative Engines are how we get there.
Not through better prompts. Through better architecture.
Unsolved Challenges
While these implementations demonstrate significant improvements in content quality, several challenges remain:
Current Limitations:
- Computational overhead: Multi-agent voting increases generation time by 3-5x
- Cost scaling: Test systems require $30-50/day for moderate volume
- False rejection rate: ~5% of quality content gets incorrectly flagged
- Domain specialization: Patterns optimized for one domain may not transfer
Open Questions We’re Working Through:
- Can we achieve similar quality with fewer model calls through intelligent routing?
- How do we measure “creativity” versus “correctness” in generated content?
- What’s the optimal balance between automation and human oversight?
- Can meta-cognitive improvements be transferred between different Creative Engines?
- How do we prevent Creative Engines from learning to game their own quality metrics?
Areas for Future Exploration:
- Federated learning across multiple Creative Engines
- Adversarial quality testing (engines that detect slop in other engines)
- Cross-modal coherence (maintaining narrative across text, image, video, audio)
- Emergent capability detection (when do engines develop unexpected abilities?)
These are genuine challenges encountered in implementations—not academic exercises but real problems that affect deployment and scaling.
*This article is the first in a seven-part series exploring Creative Engine architecture. The patterns described come from experimental implementations of multi-platform content generation, autonomous AI systems, and intelligent creative tools.
For deeper insights into AI system design, see the forthcoming “From Blueprint to Application: The Complete Guide to Enterprise Prompt Engineering” by Fredrik Bratten and co-author Saša Popović, to be published by HultMedia in 2025.*
Next in series: Quality Assurance Architecture - Building AI Systems That Police Themselves